

SRE的火热程度在当下的互联网企业 IT 行业降本增效大环境中异常突出。
不仅是薪资经常拿来与运维、研发做比较,而且在技术能力拓展和职业天花板的业内讨论中,SRE也在越来越高频出现,在国内企业,企业 IT 研发兼做 SRE 可以,运维做 SRE 也可以,再加上各行业数字化程度的逐渐提高,对 SRE 人才的需求也逐渐推高,非常多企业 IT人也将目光看向SRE,考虑转型方向与职业目标。

SRE站点可靠性工程师据说要花50%的时间来参与与软件运营相关的工作,另外50%的时间用于开发工作,如增加新功能等工作。
既要解决问题、随叫随到和人工干预,又要保证所负责的软件系统需要高度自动化和自我修复,SRE 到底是什么?国内SRE工程师的都在做什么?我们希望通过相关信息的梳理,讲清SRE这件事。
站点可靠性工程的概念由 Google 工程团队的 Ben Treynor Sloss 第一个提出。
SRE维基百科解释为站点可靠性工程(英语:Site reliability engineering,SRE)是一门将软件工程应用于基础设施以及运营的学科,该概念由Google于2003年提出。站点可靠性工程主要目标是创建可扩展和高可用性的软件系统。
Google SRE诞生之初旨在满足Google全球庞大服务的稳定性保障诉求,它的 SRE完整系统与架构是复杂且强大的,不仅具备基础设施的管控能力,还能协调 IT资源的调度,独特且难以复制。
在国内,大家通常默认站点可靠性工程(SRE)是 IT 运维的软件工程方案与负责工程师。SRE 团队使用软件作为工具,来管理系统、解决问题并实现运维任务自动化。非常多的企业SRE部门与传统运维部门职责类似,负责的是互联网服务背后的技术运维工作。部分区别于传统的运维SRE,需要思考在业务研发团队落地SRE,以软件工程的方法论重新定义研发运维,驱动并赋能业务演进。

*阿里云 ECS SRE体系大图
在执行层面,创建可扩展和高度可靠的软件系统时,SRE 可以帮助企业通过代码管理大型系统,对于管理成千上万台机器的系统管理员(sysadmin)来说,代码更具可扩展性和可持续性。因此,企业在实践 SRE的背景下,标准化和自动化通常是 SRE 工程师们比较重视的部分,比如当下从传统 IT 运维方案迁移至云原生方案的趋势, SRE 也是在不断在追求自动化的同时需要平衡满足企业需求与用户体验。
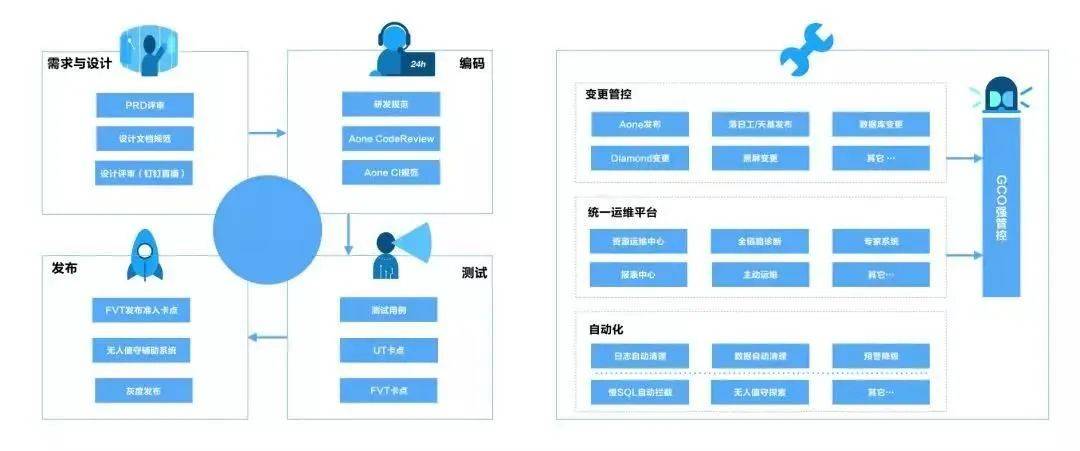
*阿里云 ECS SRE流程体系建设
在逛了各大厂的 SREJD 之后,我们发现SRE的工作大部分都在平衡软件开发和运维运营之间的差距,以此保障企业能够研发和维护高稳定、可扩展和可靠的系统。
国内的一线互联网公司如BAT、美团也都逐步从组织架构、招聘上均有体现。以阿里、字节为例为例,不同的BU均有设置SRE团队,并且在不同的业务部门,SRE的职责划分也不尽相同。
虽然在线各大厂发布的JD各不相同,但是能力要求是类似的,各一线大厂对 SRE 的工作要求集中在:
网络层(VPN、专线、防火墙、http协议、Tcp协议、BGP协议等)
中间件(接入层、消息队列、缓存、文件存储、搜素、大数据等)
容器(容器编排、容器、容器网络、镜像管理等)
操作系统(CPU管理、内存管理、磁盘I/O、网络I/O、内核等)
基础服务(日志、监控、容器云等)
除此之外,还需要和各条业务线对接,梳理需求、推动项目进展、做好故障预防、故障发现、故障定位、故障恢复、故障改进。虽然SRE专注于确保大规模系统的可用性、性能和效率,但落到企业日常执行层面,通常国内的SRE工作内容还是基于网络的服务或应用程序。
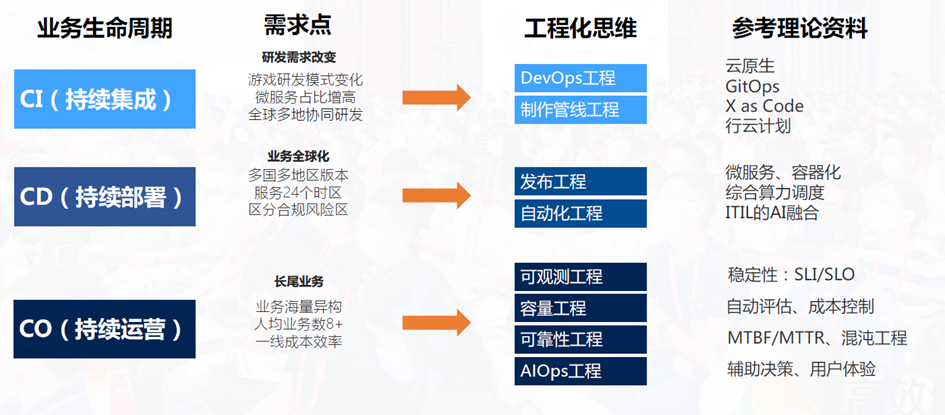
*腾讯SRE平台工程+SRE服务体系驱动业务转型
与开发团队紧密合作,设计、实施和维护高度可靠的系统。使用自动化,监控和主动措施来防止和缓解故障事件,以此实现更高的服务水平目标(SLOs),满足用户期望,保持运维和开发工作之间的平衡是 SRE 的主要工作,通过设置可接受的服务中断的阈值,为系统改进分配资源,同时保持高水平的服务可靠性。
随着云计算的普及,云计算作为基础设施会筛选淘汰过滤掉非常多的机房、网络、OS层面引发的问题,由此SRE的重点必然将转向用软件工程的方法论来重新定义运维,使用自动化来提高效能。
Netflix也曾提出CORE SRE的概念,C是Cloud,Netflix是run on AWS,Cloud是基础。Operation是运维,用少量的SRE支撑大规模服务背后的最核心理念,Netflix给出的实践答案是自动化,这也将是未来的的趋势之一。
SRE 无论是在国内还是国外,目前都算是 DevOps 的实际应用场景。和 DevOps 一样,SRE 和 DevOps 都致力于搭建开发团队和运维团队之间的互通桥梁,以便加快交付服务。
DevOps 是指对企业文化、业务自动化和平台设计等方面进行全方位变革,从而实现迅捷、优质的服务交付,提升企业价值和响应能力。SRE 可视为 DevOps 的实施。DevOps 和 SRE 实践都可以实现更快的应用开发生命周期、改进的服务质量和可靠性,以及缩短的 IT 应用开发时间等优势。
然而,SRE 与 DevOps 有所不同的地方在于,在编码和构建新功能时,DevOps 专注于有效通过开发流程,而 SRE 专注于通过创建新功能来平衡站点可靠性,并且SRE 需要解决通信和工作流程问题的运维背景,兼具开发团队和运维团队的技能。
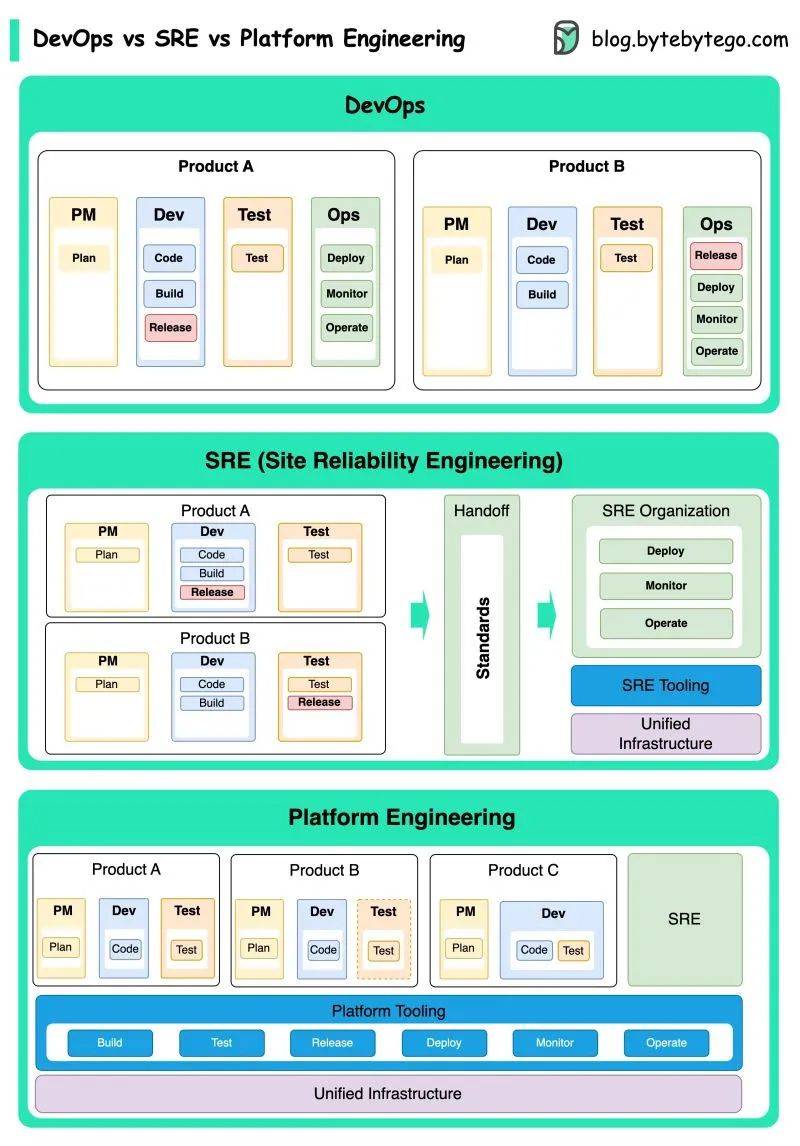
在国内,SRE 是传统 IT 角色或系统管理角色与 DevOps 交汇的地方。在传统的 IT 环境中,组织可能拥有一组管理复杂系统的系统管理员。重点和责任是确保软件部署得当,为最终用户提供可靠的服务。但是,系统管理员并不关注实际的软件开发,而实际软件开发与系统管理员角色可能会产生分歧。
在这个交汇点,就需要依靠SRE工程师的角色确保开发工作高效可靠,避免意外情况发生。SRE 角色往往是企业 IT的“扫地僧”角色。上一分钟 SRE 可能会在 AWS 中预配存储,下一分钟 SRE 可能需要与客户交谈或为新项目编写一些 Python 代码。

国内互联网行业的快速增长带来了对企业 IT 强大和可扩展系统的众多需求。为了满足这些需求, SRE已经成为国内企业IT部门不可或缺的角色,面对高用户流量、合规管理和激烈的市场竞争,越来越多地企业开始采用SRE实践,建立专门的SRE团队,并将SRE原则纳入其开发流程。
各家SRE团队也在缓解各企业重大 IT事件中做出了示范,确保服务正常运行时间,并提高系统性能。
期待大家在 SRE 领域积累更多适合中国企业的经验,并分享出来。
引用资料与参考信息版权归原作者所有:
https://www.redhat.com/zh/topics/devops/what-is-sre SRE 运维:一文理解站点可靠性工程是什么?
https://aws.amazon.com/cn/what-is/sre/ 什么是站点可靠性工程- SRE 简介 - Amazon AWS
https://mp.weixin.qq.com/s/pMzOGqqXKgdH30bNhN72LQ阿里巴巴技术专家:大型团队如何从 0 到 1 自建 SRE 体系
https://mp.weixin.qq.com/s/xHkrKeZrmNG8kVuibYkfGA以阿里为例,详解SRE的团队建设与职能分工
https://mp.weixin.qq.com/s/DUfoMeJa0spHO0d1p0RSdQ这是阿里技术专家对 SRE 和稳定性保障的理解
https://blog.csdn.net/weixin_42556618/article/details/130243812 2023 GOPS 腾讯蓝鲸:大型SRE组织设计与建设落地
https://blog.bytebytego.com/p/ep-52-devops-vs-sre-vs-platform-engineering EP52: DevOps vs. SRE vs. Platform Engineering
最后,我们搜集了部分 SRE 面试题以及微博运维团队、七牛云运维团队、阿里巴巴 SRE、搜狗团队、滴滴团队的实践分享资料,有需要的 IT 小伙伴可以私信❤️熊局( itjuneiren)获取。

PS. 如果你也是IT人,或是想要进入IT行业的小伙伴,欢迎你加入我们IT局内人的线上社群,在这里,你可以收获技术大咖的经验知识分享,和同行人交流共享资源,甚至是碰撞出美妙的合作火花~赶紧扫码进群吧!


